{kind=link}
Это руководство призвано поддержать разработчикам улучшить производительность в играх, сделанных на Unreal Engine 4 (UE4). Тут мы расскажем об инструментах, которыми можно пользоваться и в самом движке, и за его пределами, о наилучших подходах в использовании редактора, а также о скриптинге, помогающем повысить фреймрейт и стабильность проекта.
Общая цель этого руководства – установить из-за чего возникают проблемы с производительностью и предложить несколько методов для их решения.
При написании этого руководства использовался UE4 версии 4.14.
Колы измерения
Для измерения оптимизационных улучшений используются кадры в секунду (эту кол измерения также называют «фреймрейтом» или «фпс») и миллисекунды на кадр («мс»).
График ниже демонстрирует отношение между средним фреймрейтом и миллисекундами.
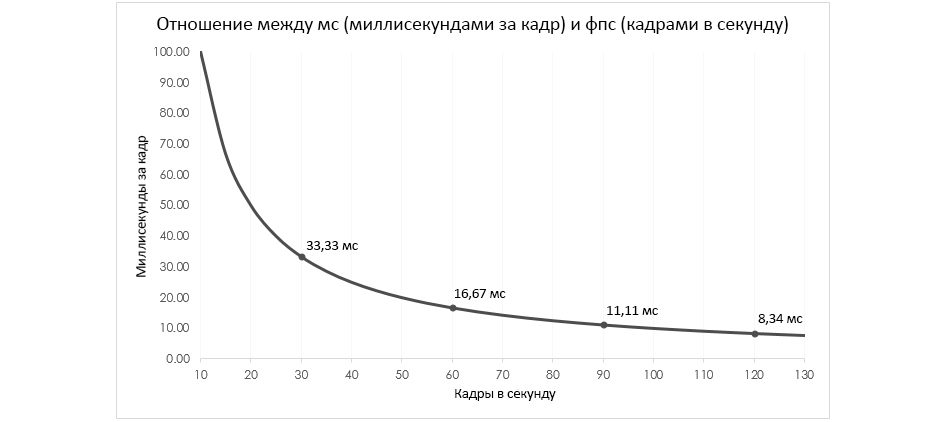
Чтобы разузнать мс при каком-либо фпс, просто узнаем величину, обратную фпс (т.е. берем 1 и делим ее на фпс), а затем умножаем ее на 1000.
1/ФПС x 1000 = МС
Использование миллисекунд для описания улучшений в производительности позволяет лучше измерить степень оптимизации, необходимый для достижения целевого фреймрейта.
Вот пара образцов увеличения фпс на 20 кадров в секунду:
- Чтобы поднять фпс с 100 до 120, необходимо улучшить результат на 1,66 мс
- Чтобы поднять фпс с 10 до 30, необходимо улучшить результат на 66,67 мс
Инструменты
Перед тем, как начать, подавайте рассмотрим три инструмента – чтобы понять, что происходит под капотом движка. Это UE4 CPU Profiler, UE4 GPU Visualizer и Intel Graphics Performance Analyzers (Intel GPA).
Profiler
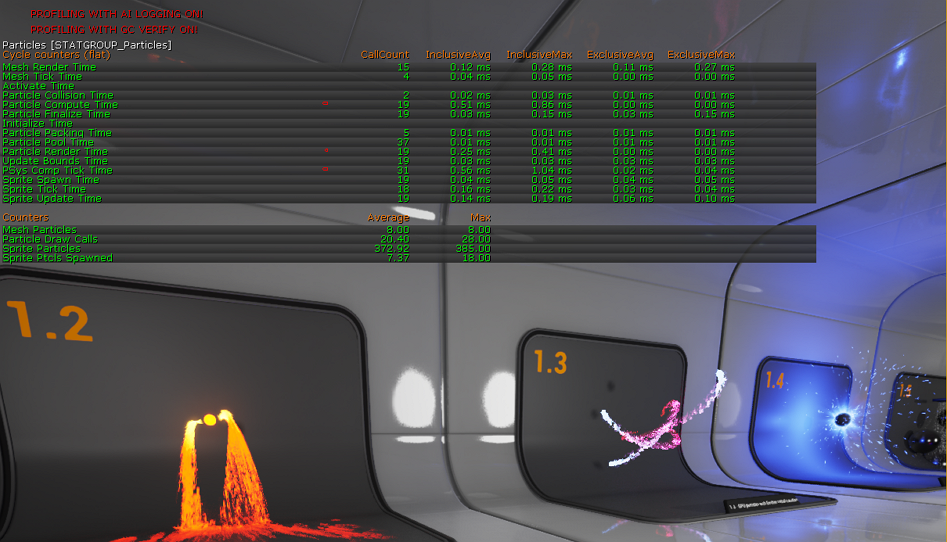
UE4 CPU Profiler – это инструмент, какой встроен в UE4 и позволяет отслеживать производительность в игре, будь это игра вживую или попросту сохраненный фрагмент.
Чтобы найти Profiler, кликните в UE4 на Window > Developer Tools > Session Frontend.
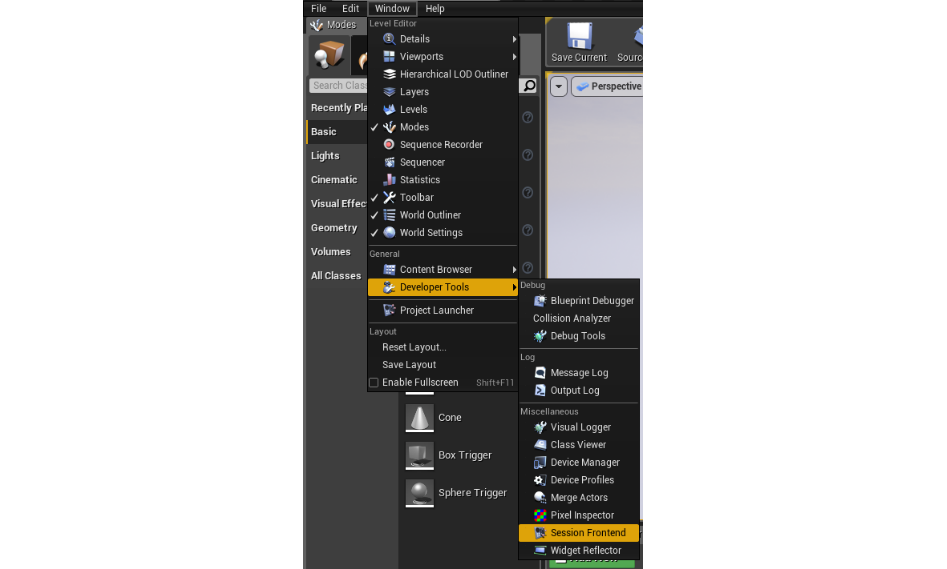
Как добраться до окна Session Frontend
В Session Frontend изберите вкладку Profiler.
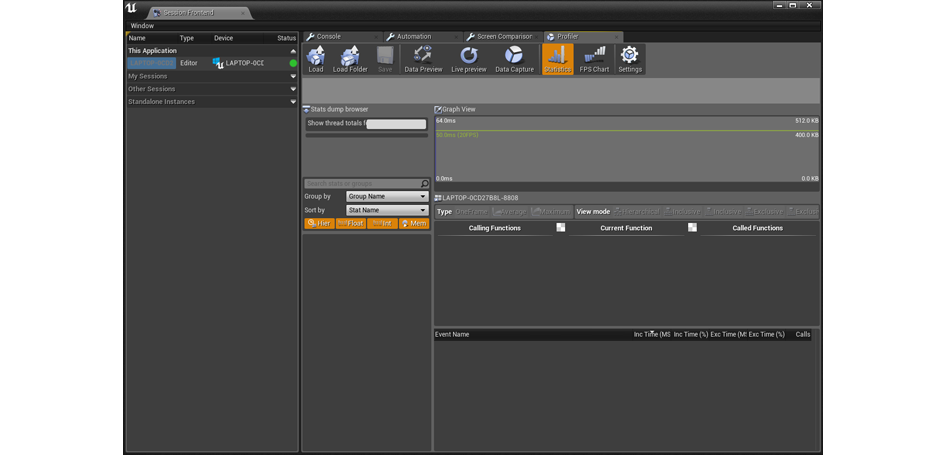
Profiler в Unreal Engine
Теперь, когда вы в окне Profiler, изберите Play-In-Editor (PIE), а затем выберите Data Preview и Live Preview, чтобы увидать данные, считываемые с игры. Чтобы начать захват этих, нажмите Data Capture, а чтобы сохранить эти данные для дальнейшего просмотра, отожмите Data Capture.
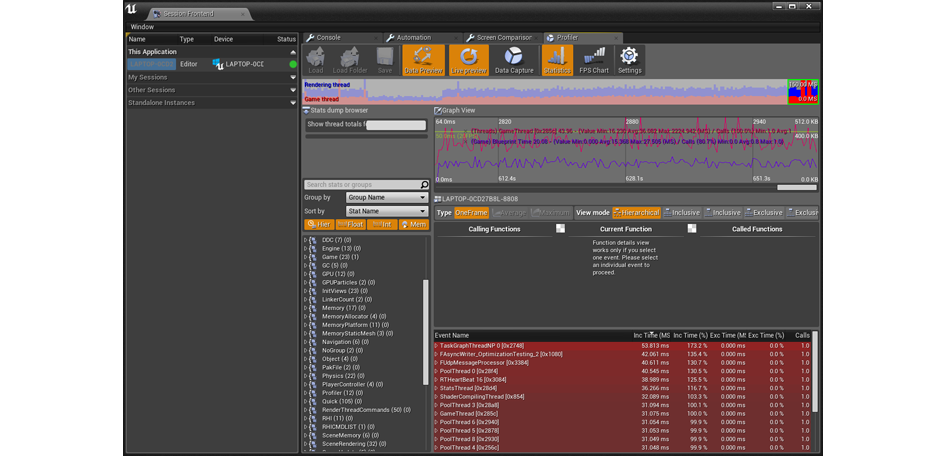
Просмотр процессов сквозь Profiler
В Profiler каждое действие и команда отражаются в миллисекундах. Любую область можно изучить на предмет того, как она влияет на фреймрейт проекта.
Немало подробно о Profiler читайте в документации Epic.
GPU Visualizer
UE4 GPU Visualizer определяет, сколько вычислительных ресурсов требуется на хода рендеринга (от «rendering pass»), а также позволяет во всех деталях просматривать, что происходит в пределах того или иного кадра.
Отворить GPU Visualizer можно через консоль разработчика, вписав туда «ProfileGPU».

Консольная команда ProfileGPU
После того, как вы впишите команду, покажется окно GPU Visualizer. В нем демонстрируется, сколько времени занимают хода, а также примерное расположение этих проходов.
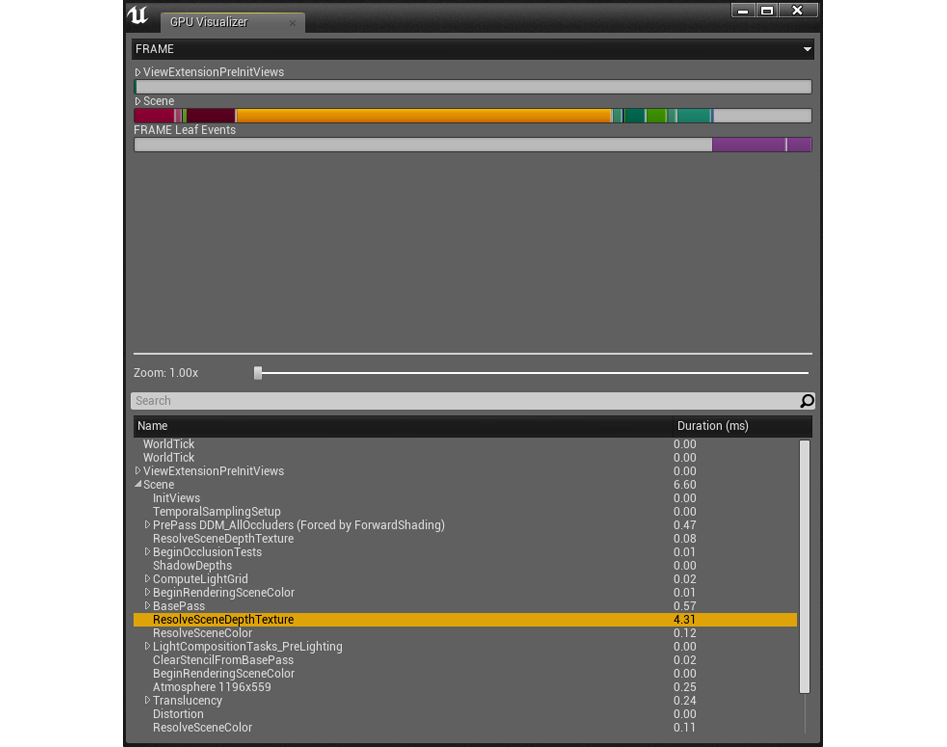
Просмотр процессов сквозь GPU Visualizer
Как и в Profiler, определив участки, которые обрабатываются длиннее остальных, вы поймете, где заняться оптимизацией.
Более подробно о GPU Visualizer декламируйте в документации Epic.
Intel GPA
Intel Graphics Performance Analyzers (Intel GPA) – это комплект инструментов для анализа и оптимизации, призванных помочь разработчикам сделать свои графические проекты немало производительными.
В этом руководстве мы сфокусируемся на двух аспектах этого комплекта: Analyze Application и Frame Analyzer. Для начала загрузите GPA с Intel Developer Zone. Введя, скомпилируйте свой проект с настройкой Development (чтобы избрать ее, кликните на File > Package Project > Build Configuration > Development).
Когда проект скомпилируется, запустите Graphics Monitor, кликните на пункт Analyze Application, изберите нужный файл *.exe в поле Command Line и, нажав на кнопку Run, запустите его.
Дальше запустится игра – так же, как запускается обычно, однако в левом верхнем углу сейчас будет меню со статистикой. Чтобы расширить его, кликните Ctrl+F1. Если нажать на Ctrl+F1 одинешенек раз, появится несколько окошек с показателями, измеряемыми в реальном поре. Если нажать Ctrl+F1 еще раз, появится список команд (плюс горячие клавиши, какие нужно нажать для их выполнения), с помощью которых можно экспериментировать c игрой, пока та будет запущена.
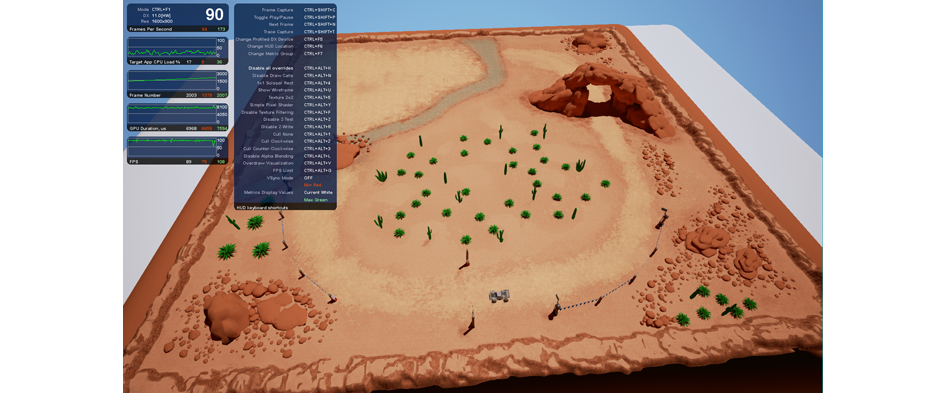
Меню Intel GPA в игре
Чтобы сделать кадр для последующего разбора в Frame Analyzer, нужно зайти в игру и сделать два добавочных действия.
Сначала включите Toggle Draw Events. Чтобы сделать это, впишите в консоли «ToggleDrawEvents».

Консольная команда ToggleDrawEvents
Когда вы включите эту функцию, командам отрисовки, шагающим от движка, будут присваиваться названия. Это позволит понимать что к чему, когда вы будете глядеть на захваченный кадр в Frame Analyzer.
Наконец, сохраните кадр, нажав на горячие клавиши Ctrl+Shift+C.
Сохранив кадр, запустите Graphics Monitor, кликните на пункт Graphics Frame Analyzer и изберите кадр, который нужно загрузить. После того, как сохранение будет завершено, программа покажет всю информацию о графике, имеющейся в кадре.
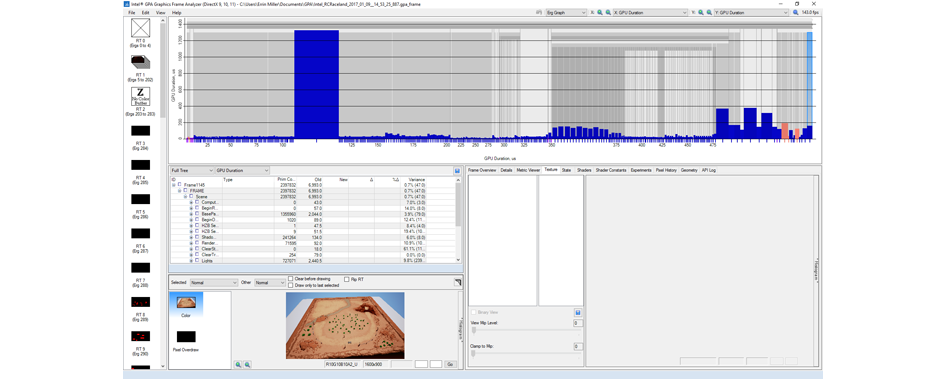
Intel GPA
Немало подробно об Intel GPA читайте в документации Intel.
Пример использования Intel GPA
Обилие этих в Intel GPA поначалу кажется сложным, поэтому давайте начнем с самых вящих фрагментов информации. В правом верхнем углу окна выставьте обе оси (X и Y) на GPU Duration – в итоге получится график того, какие команды отрисовки в этом кадре являются наиболее ресурсоемкими.
В нашем образце, т.е. в кадре с пустынным ландшафтом, видно, что самым ресурсоемким вышел базовый проход. Выбрав самый большой пик на графике (то есть, в сути, самую ресурсоемкую команду отрисовки), а также пункт Highlighted в левом нательном превью-окне (оно называется Render Target Preview), мы видим, что вином пика стал ландшафт (он подсвечен розовым цветом).
Дальше, перейдя в окно Process Tree List (оно находится рослее превью-окна и показывает список процессов), чтобы найти избранную команду отрисовки, мы видим, что этот ландшафт состоит из 520200 примитивов, а на его обработку у GPU (это и есть показатель GPU Duration) уходит 1,3185 миллисекунд (мс).
Розыск самой ресурсоемкой команды отрисовки в кадре
Теперь, когда мы ведаем, что стало причиной пика, можно приступить к оптимизации.
Во-первых, ландшафт можно пересобрать при поддержки режима Manage у инструмента UE4 для создания ландшафтов, что позволяет снизить число примитивов до 129032, а GPU Duration – до 0,8605 мс. Таким образом, подмостки оптимизируется на 5%.
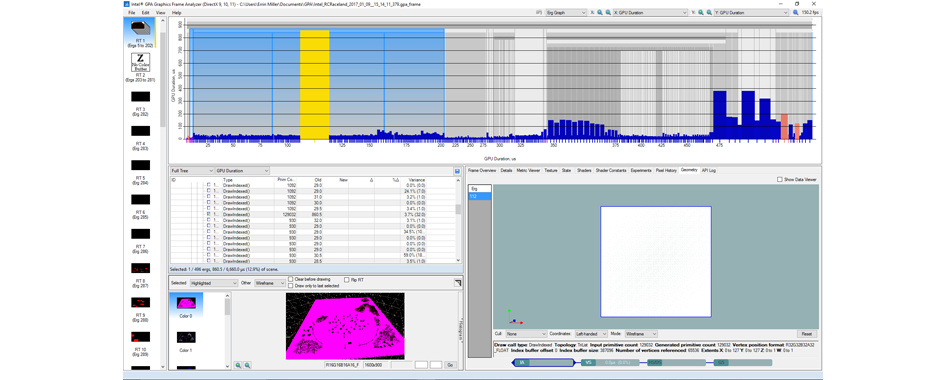
Видим уменьшение GPU Duration
Чтобы снова снизить ресурсную «стоимость» ландшафта, подавайте взглянем на материалы. Наш ландшафт использует материал с 13 текстурами 4096 x 4096 (4K), и в итоге на текстурный стриминг приходится в целом 212,5 Мб.
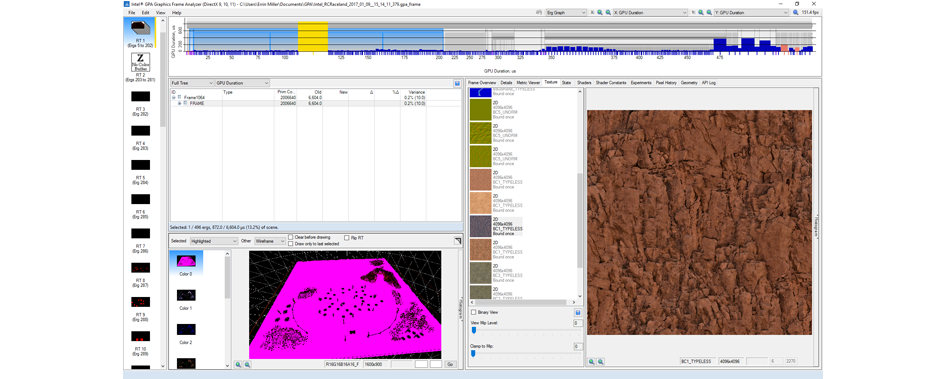
Просмотр отрендеренных текстур в Intel GPA
Сдавив все ландшафтные текстуры до 2048 х 2048 (2K), мы сократили GPU Duration до 0,801 мс и улучшили производительность на добавочные 6%.
В итоге снижение текстурного стриминга для ландшафта до 53,1 Мб и уменьшение числа примитивов позволили сделать проект немало быстрым. И все это ценой лишь очень небольшого снижения визуального качества ландшафта.
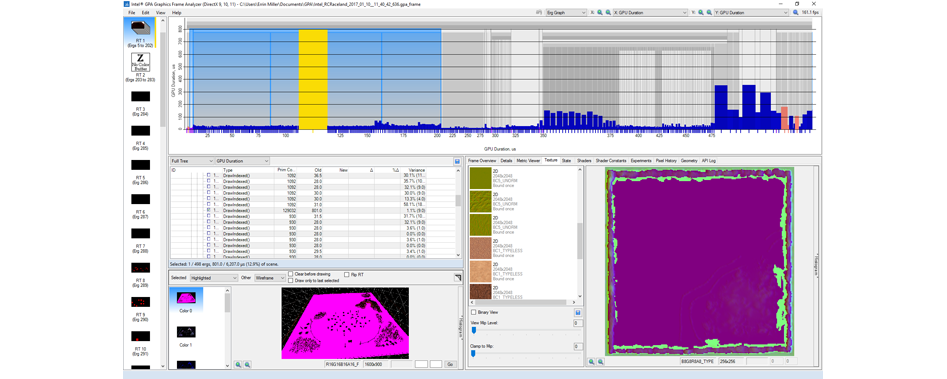
Видим снижение GPU Duration, достигнутое благодаря снижению размера текстур
В цельном, просто пересобрав сцену и изменив текстуры, мы сумели добиться следующего:
- Снизили GPU Duration при обработке ландшафта на 40 % (с 1,3185 до 0,801 мс)
- Улучшили фпс на 18 кадров (с 143 до 161)
- Снизили мс на 0,7 миллисекунд
Оптимизация в редакторе
Forward Rendering против Deferred Rendering
Deferred Rendering – это типовой метод рендеринга, используемый в UE4. Он дает наилучшую картинку, но ухудшает производительность, особенно в ВР-играх и на компьютерах низенькой ценовой категории. В данных случаях разумнее будет переключиться на Forward Rendering.
К образцу, в сцене Reflection из магазина Epic можно заметить что между рендерингом методами Deferred и Forward есть отдельный отличия.

Сцена Reflection, отрендеренная методом Deferred

Подмостки Reflection, отрендеренная методом Forward
Сцена Reflection, отрендеренная методом ForwardПри Forward-рендеринге мучатся отражения, освещение и тени, но остальные визуальные элементы не меняются. В итоге производительность улучшается, но необходимы ли такие жертвы, решать, разумеется, вам.
Если взглянуть в Intel GPA на кадр из этой подмостки, отрендеренной методом Deferred, мы увидим, что сцена работает на 103,6 мс (9 фпс), и порядочную часть этого времени занимает обработка освещения и отражений.
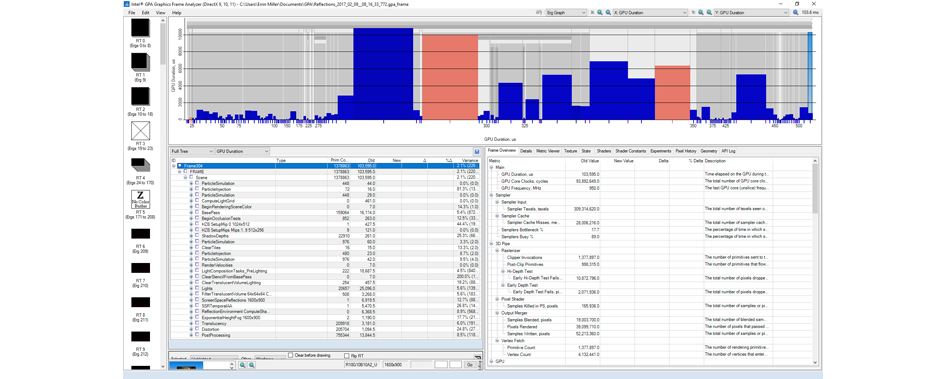
Эти о кадре из сцены Reflection, отрендеренной методом Deferred на Intel HD Graphics 530
А если взглянуть на кадр, отрендеренный методом Forward, мы увидим, что показатель «мс» улучшился с 103,6 до 44,0 (т.е. на 259%), а вяще всего времени уходит на базовый проход и пост-обработку, над оптимизацией каких тоже можно поработать.
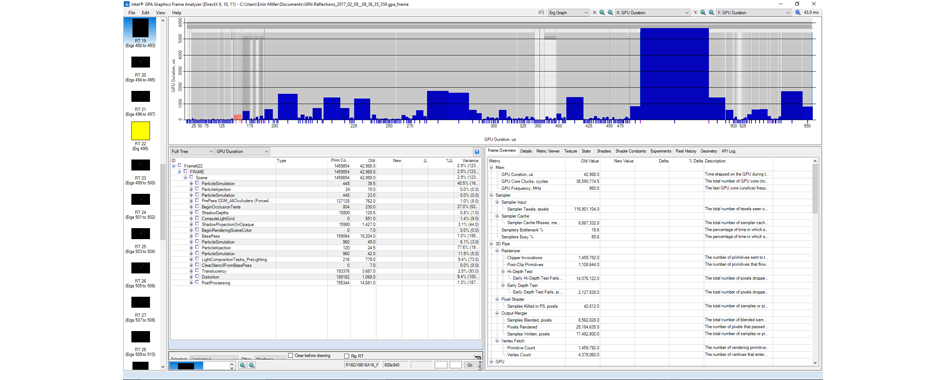
Данные о кадре из сцены Reflection, отрендеренной методом Forward на Intel HD Graphics 530
Степень детализации
Статические сетки в UE4 могут состоять из тысяч или даже сотен тысяч треугольников – чтобы показать самые тончайшие детали, которыми 3D-художник украсил свою работу. Однако, когда игрок есть далеко от модели, он этих деталей не видит, а движок эти треугольники по-прежнему возделывает. Чтобы решить эту проблему и тем самым оптимизировать игру, мы можем использовать так именуемые «уровни детализации» (или просто LOD – от англ. «level of detalization»), чтобы на ближнем расстоянии эти детали показывались, а на далеком – нет.
Генерация LOD
В стандартном пайплайне LOD’ы создаются 3D-моделлером еще при создании самой модели. Желая этот метод позволяет контролировать конечный результат, в UE4 встроен отличный инструмент для самодействующей генерации LOD’ов.
Автогенерация LOD’ов
Для этого выберите нужную модель, перебегите во вкладку Details, а затем к пункту LOD Settings. Там найдите пункт Number of LODs (т.е. число уровней детализации) и впишите туда нужное значение.

Самодействующая генерация уровней детализации
Кликните на Apply Changes. Для движка это сделается сигналом для генерации нескольких LOD’ов, и оригинальной моделью среди них будет LOD0. В образце ниже показано, что при создании пяти LOD’ов количество треугольников у нашей статической сетки уменьшается с 568 до 28 – это порядочное снижение нагрузки на GPU.

Количество треугольников и вершин, а также размер на экране для любого LOD’а
Если разместить эту модель на сцене, мы увидим, как она будет меняться при удалении от камеры.

Визуальная демонстрация LOD’ов, показанная в подневольности от размера на экране
Материалы для LOD’ов
Еще одна функция LOD’ов – это то, что каждый из них может использовать собственный материал. Это позволяет еще вяще снизить «стоимость» статической сетки.
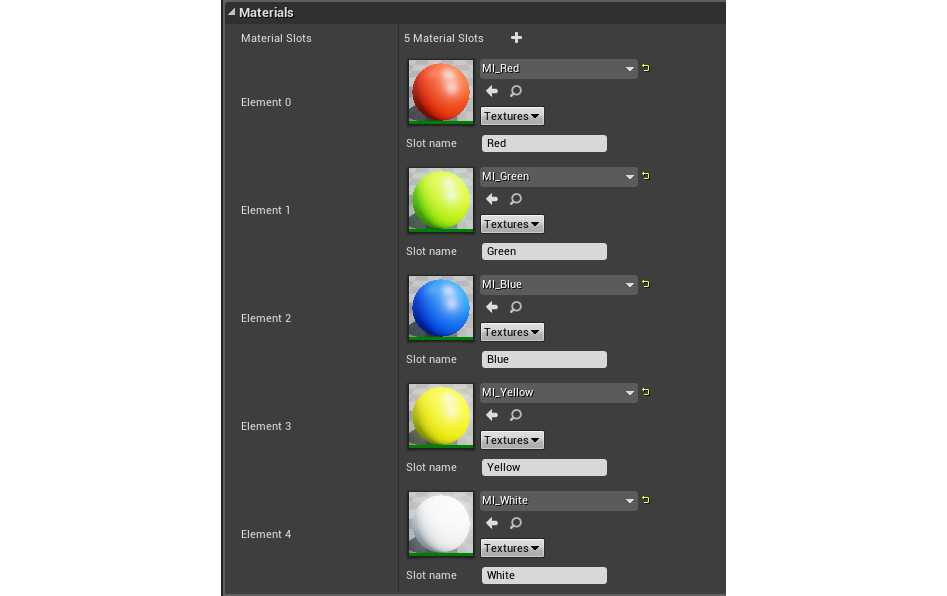
Материалы, присвоенные любому уровню детализации
К примеру, в игровой индустрии повсеместно используются карты нормалей. Однако в ВР возникает проблема – карты нормалей не идеальны, поскольку при ближайшем рассмотрении игрок видит, что это просто плоская поверхность.
Эту проблему можно разрешить при помощи LOD’ов. Поскольку LOD0 детализирован до такой степени, что на нем видны мелкоте вроде болтов и шурупов, когда игрок рассматривает этот объект вблизи, то чувствует более сильный эффект погружения. Поскольку все эти детали смоделированы, на первом LOD’е от карты нормалей можно отказаться. Когда игрок удаляется от этого объекта, движок переключается на иной LOD, на котором как раз стоит карта нормалей, снижающая детализацию модели. Когда игрок удалится еще дальней, карту нормалей можно убрать, потому что она станет чересчур маленькой и ее попросту не будет видно.
Статические сетки-экземпляры
Любой раз, когда на сцене появляется новый объект, это требует вызова добавочной команды отрисовки на устройстве, обрабатывающем графику. Если это статическая сетка, то для любой копии этой сетки потребуется отдельный вызов команды отрисовки. Одинешенек из способов оптимизировать это (т.е. ситуацию, когда одна и та же статическая сетка повторяется на сцене несколько раз) – создать экземпляры статических сеток и тем самым снизить число вызываемых команд отрисовки.
К примеру, у нас есть две сферы, заключающиеся из 200 восьмигранных сеток – одна зеленая, а другая кубовая.

Сфера из статических сеток и сеток-экземпляров
Зеленые восьмигранники – это обыкновенные статические сетки. Это значит, что для генерации каждой из этих моделей используется отдельный комплект команд отрисовки.

Команды отрисовки для 200 статических сеток (максимум – 569)
Кубовые восьмигранники – это сетки-экземпляры. Это значит, что для генерации всех этих моделей использовался лишь один набор команд отрисовки.
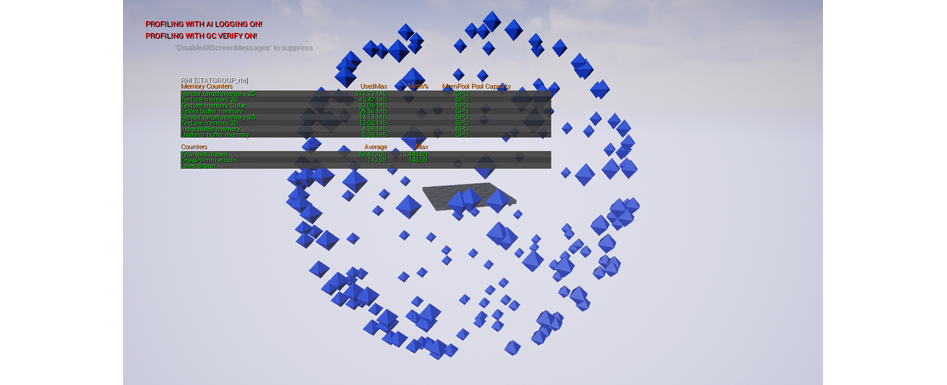
Команды отрисовки для 200 сеток-экземпляров (максимум – 143)
Если взглянуть на оба образца через GPU Visualizer, то базовый проход для зеленой (со статическими сетками) сферы занимает 4,30 мс, а для кубовее (с сетками-экземплярами) – 3,11 мс. Таким образом, мы оптимизируем сцену на 27%.
О сетках-экземплярах необходимо знать одну вещь – если у такой сетки рендерится какая-то доля, она будет рендериться и у всех остальных «клонов» этой сетки. То есть, если какой-то из «клонов» оказывается за пределами камеры, наш оптимизационный потенциал растрачивается впустую. Потому рекомендуем делать сетки-экземпляры небольшими кучками – вроде груды камней, груды мешков для мусора, горы коробок или модульных зданий, находящихся поодаль.
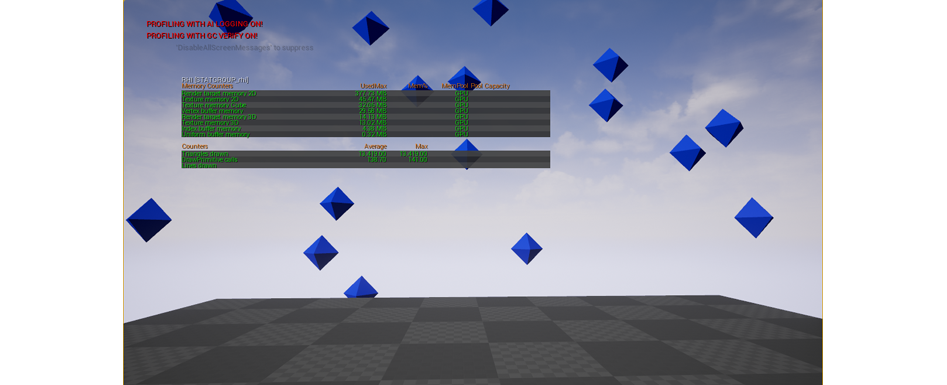
Если большинство сеток-экземпляров есть за кадром, они по-прежнему рендерятся
Иерархические статические сетки-экземпляры
Если вы используете статические сетки с LOD’ами, обратите внимание на иерархические сетки-экземпляры.
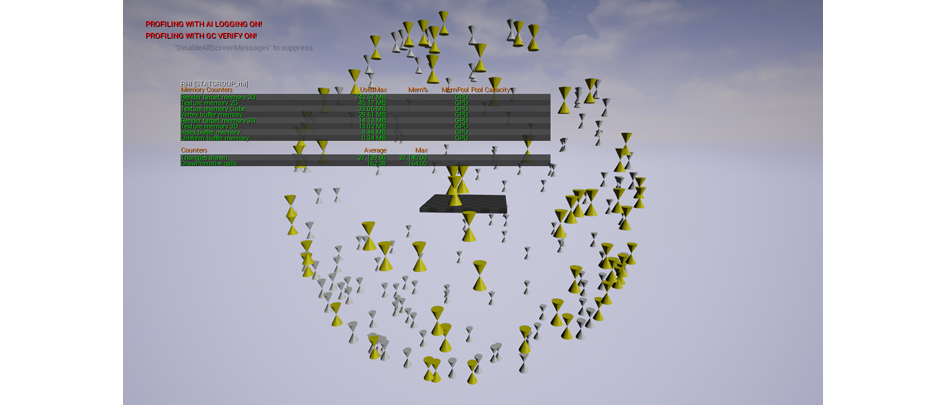
Сфера из иерархических сеток-экземпляров с LOD’ами
Как и типовые сетки-экземпляры, иерархические сетки-экземпляры снижают количество команд отрисовки, но также используют информацию о LOD’ах.

Сфера из иерархических сеток-экземпляров с LOD’ами; вид вблизи
Occlusion Culling
В движке UE4 функция Occlusion Culling – это система, позволяющая сделать так, чтобы объекты, какие игрок не видит, не рендерились. Это позволяет снизить системные заявки к игре, поскольку движку больше не приходится рисовать безотносительно все объекты абсолютно во всех сценах и абсолютно во все кадрах.

Восьмиугольники, раскиданные по сцене
Чтобы видеть загороженные объекты (они будут показаны сквозными кубами с зелеными краями), в консоли редактора введите «r.VisualizeOccludedPrimitives 1». Чтобы выключить эту настройку, вместо «1» впишите «0».

Кромки загороженных сеток; эти края стали видны после использования команды r.VisualizeOccludedPrimitives 1
То, будет сетка рендериться или нет, зависит от так именуемого «граничного куба» (от англ. «bounding box»). Благодаря ему отдельный объекты могут быть невидимы для игрока, но видны для камеры – в таком случае движок принимает решение рендерить эти объекты.

Просмотр рубежей объекта в окне для работы с объектом
Если сетку необходимо отрендерить до того, как ее увидит игрок – например, для рендеринга анимации бездействия (от англ. «idle animation», это анимация персонажа, какая активируется, когда он стоит на месте и ничего не делает; это может быть чесание потылицы, ковыряние ногой в земле и т.д.) – то размер граничного куба можно повысить. Это можно сделать в окне для работы с объектом, в меню Static Mesh Settings. Разыскивайте там пункты Positive Bounds Extension и Negative Bounds Extension.
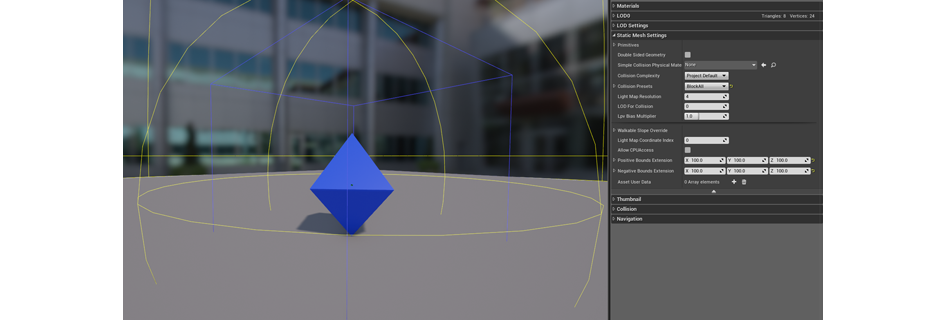
Задаем масштаб для рубежей объекта
Граничный куб сложных сеток и фигур всегда сходит за пределы этих сеток, поэтому чем больше пустого пространства будет в граничном кубе, тем пуще эти сетки будут рендериться. Таким образом, работая над сценой, значительно знать, как размеры граничных кубов влияют на ее производительность.
Подавайте представим мысленный эксперимент, где мы создаем 3D-модель, а затем экспортируем ее в UE4. Как нам прийтись к созданию арены в стиле Колизея?
Допустим, игрок стоит в середине арены и оглядывает огромный Колизей, пытаясь запугать своих противников. Когда игрок вертит камеру, то ее направление и ракурс будут диктовать то, что движку необходимо рендерить. Поскольку Колизей – это очень важный элемент нашей игры, мы сделали его весьма детальным, но чтобы сэкономить на командах отрисовки, его нужно сделать из нескольких объектов.
Но, во-первых, мы должны отказаться от идеи того, что вся манеж должна быть одним большим цельным объектом. В этом случае число треугольников, которые нужно будет отрендерить, будет отвечать размеру всей арены – независимо от того, смотрим ли мы на ее отдельные доли или нет. Как нам оптимизировать эту модель?
Зависит от нескольких факторов. Во-первых, от того, на какие кусочки будет порезана манеж, и во-вторых, от того, как форма этих кусочков будет воздействовать на размер граничных кубов (что важно для Occlusion Culling). Чтобы было несложнее, давайте представим, что игрок использует камеру с 90-градусным углом обозрения.
Вариант первый – «нарезанная пицца». То есть мы создаем 8 идентичных заостренных кусочков, «носы» которых направлены в центр арены. Этот метод несложен, но для Occlusion Culling он подходит не очень, поскольку в этом случае будет немало перехлестов между граничными кубами. Если игрок будет стоять в середине и смотреть вокруг, его камера будет захватывать 3-4 куба, т.е. вящую часть времени движку придется рендерить половину манежи. В самом худшем случае игрок может стать горбом к стене, посмотреть на арену вокруг него и тем самым завладеть в кадр все 8 кусочков «пиццы». Оптимизации никакой.
Вариант другой – «крестики-нолики». Здесь мы создаем 9 кусочков. Это не самый традиционный метод, но его преимущество в том, что тут нет перехлестов между граничными кубами. Как и в случае с «пиццей», если игрок будет стоять в середине арены, то захватит в кадр 3-4 кусочка. Однако, став горбом к стене, он захватит в кадр 6 из 9 кусочков, что по сравнению с «пиццей» дает кой-какую оптимизацию.
Последний вариант – «нарезанное яблоко» (1 центральный кусочек и 8 боковых). Это самый общераспространенный метод для этого мысленного эксперимента, и очень неплохой – перехлест между граничными кубами есть, но небольшой. Если игрок будет стоять в середине арены, то захватит в кадр 5-6 кусочков, но в отличие от первых двух вариантов, в самом худшем случае (вплоть спиной к стене) будут рендериться те же 5-6 кусочков.
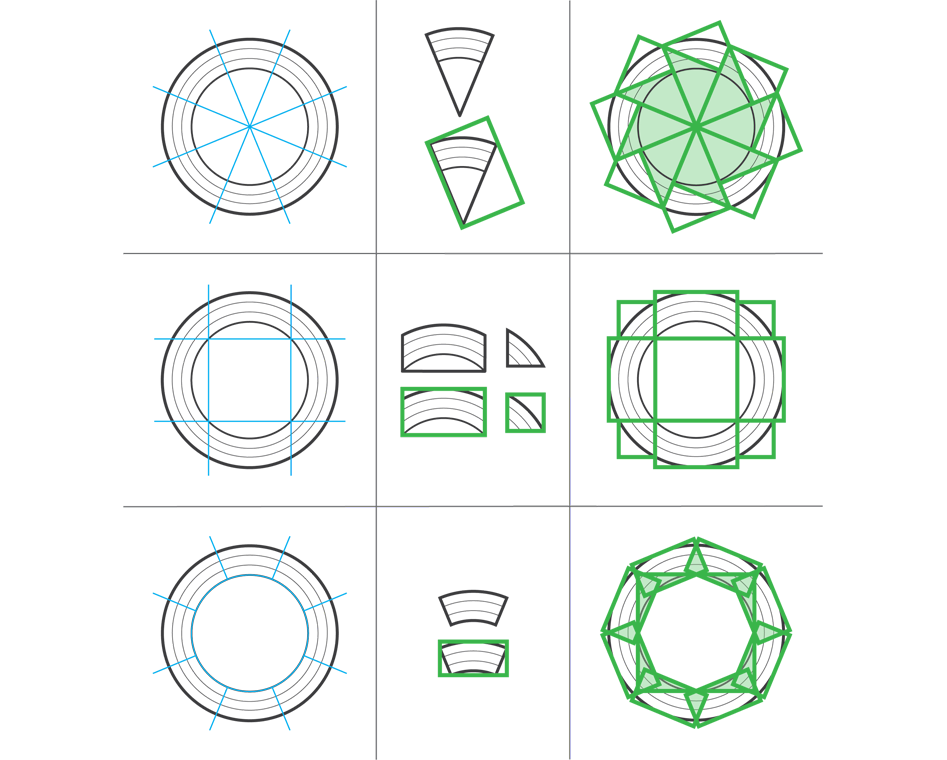
Мысленный эксперимент, демонстрирующий, как можно порезать большую модель и как это повлияет на граничные кубы и перехлесты между ними
Каскадные карты теней
Желая каскады динамических теней (от англ. «dynamic shadow cascade») добавляют вашей игре рослый уровень детализации, они могут оказаться очень «дорогостоящими» в плане производительности – чтобы резаться в такую игру без потери фреймрейта, понадобится мощный PC.
К счастью, как подсказывает наименование этой функции, эти тени создаются динамически для каждого кадра. То есть мы можем создать несколько вариантов, благодаря каким игрок сможет оптимизировать свои графические настройки.
«Стоимость» каскадов динамических теней на Intel Graphics 350

Смыслом в каскадах динамических теней можно управлять динамически. Это можно сделать несколькими способами:
- Поменяв качество теней в настройке Settings > Engine Scalability Settings > Shadows
- Отредактировав параметры в файле «BaseScalability.ini»: в настройках Shadow.CSM.MaxCascades (между «0» и «4») и sg.ShadowQuality (между «0» и «3» – для «низенький», «средний», «высокий» и «эпический»)
- Добавив нод Execute Console Command в блюпринт игры, где вы вручную поменяли параметр Shadow.CSM.MaxCascades
Оптимизация сквозь скриптинг
Отключение полностью прозрачных объектов
Команды отрисовки могут вызываться даже для целиком прозрачных игровых объектов. Чтобы избежать этого, необходимо настроить движок таким образом, чтобы он перестал их рендерить.
Чтобы сделать это при поддержки блюпринтов, в UE4 нужно задействовать несколько разных систем.
Комплект параметров для материалов
Во-первых, создаем набор параметров для материалов (или попросту MPC – от англ. «material parameter collection»). Здесь будут храниться линейные и векторные параметры, какие можно будет привязать к любому материалу в игре. Их можно использовать для модификации этих материалов ровно во время игры – для создания динамических эффектов.
Создаем MPC, кликая на вкладке Content Browser по Add New > Materials & Textures > Material Parameter Collection.
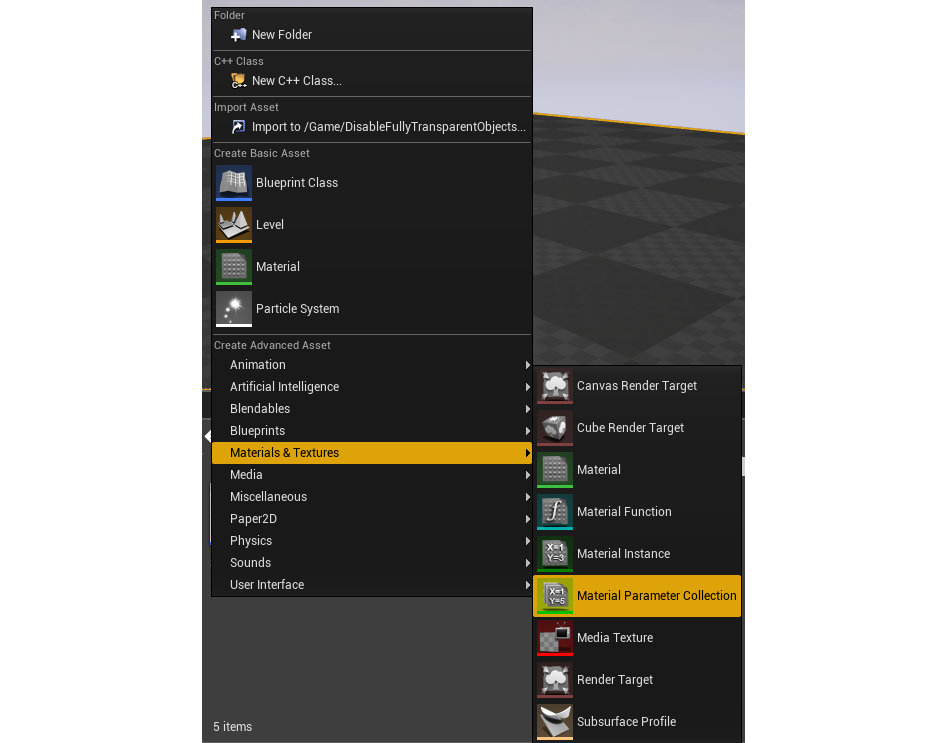
Создание MPC
Будучи в MPC, мы можем создать, наименовать и задать дефолтные значения для линейных и векторных параметров. В нашем случае потребуется линейный параметр – мы назовем его Opacity (т.е. «прозрачность») и с его помощью будем править прозрачностью нашего материала.

Задаем линейный параметр под наименованием Opacity
Материал
Далее нам нужен материал, на котором мы будем использовать MPC. В этом материале создаем нод Collection Parameter. В этом ноде выбираем MPC и то, какие параметры будут использоваться.

Розыск нода Collection Parameter в материале
Создав нод, соединяем его с параметром Opacity на базовом материале.
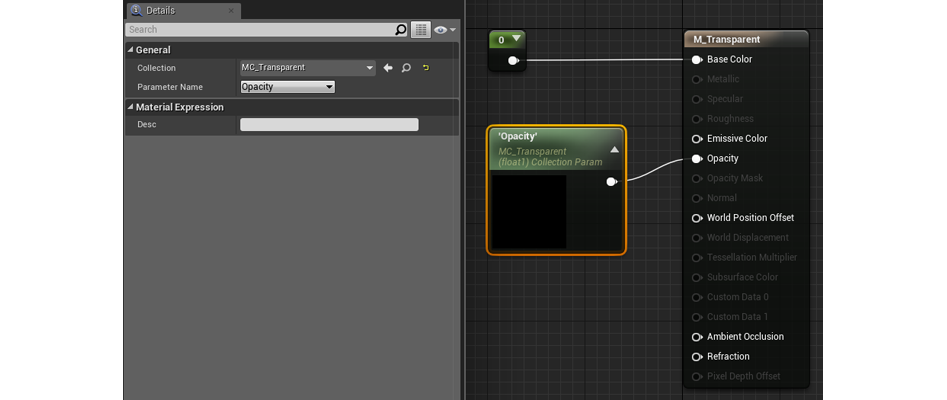
Настраиваем Collection Parameter в материале
Скрипт в блюпринте
Создав MPC и материал, закатываемся в блюпринт и настраиваем его так, чтобы можно было задавать и считывать смыслы с MPC. Это делается при помощи нодов Get/Set Scalar Parameter Value и Get/Set Vector Parameter Value. Дальше заходим в эти ноды, в пункте Collection выбираем набор, какой хотим использовать (MPC), а в пункте Parameter Name – название параметра из этого комплекта.
Для этого примера мы делаем так, чтобы линейное значение Opacity было синусом ко поре игры – чтобы видеть значения в диапазоне от «1» до «-1».

Задаем и считываем линейный параметр, а также используем его смысл в функции
Чтобы определять, рендерится объект или нет, создаем новоиспеченную функцию под названием Set Visible Opacity. Входными значениями у нее будут параметр Opacity из MPC и статическая сетка, а выходным – смысл типа Boolean, сообщающее о том, виден ли объект или нет.
Далее мы запускаем проверку на то, чтобы смысл было чуть больше «0» (в данном случае, вяще «0,05»). Проверка на «0» может сработать, но при приближении к «0» игрок вяще не сможет видеть объект, поэтому мы можем просто выключить его до того, когда смысл станет «0». Кроме того, это позволяет создать буфер – на случай промахов с плавающей точкой, из-за которых линейный параметр не сможет получить буквальный «0». К примеру, если значением будет «0,0001», эта система его попросту выключит.
Далее создаем нод Branch – если на выходе у него будет True, то и видимости объекта (верхний нод Set Visibility) будет дано смысл «true», а если False, то видимости объекта (нижний нод Set Visibility) будет дано «false».
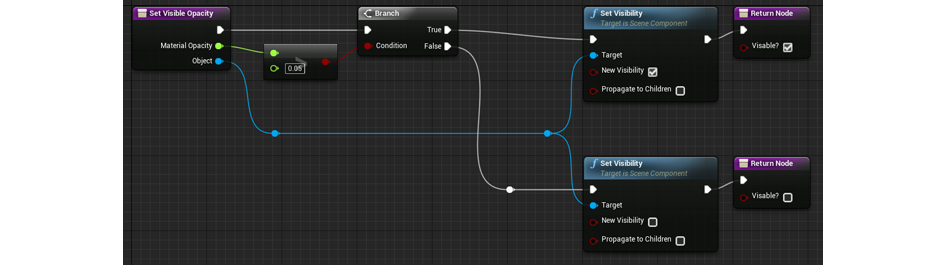
Функция Set Visible Opacity
Нод Event Tick, пора и проверка на рендер
Если в блюпринте сцены используется нод Event Tick, эти скрипты будут трудиться, даже если объектов на экране не видно. Как правило, в этом нет ничего ужасного, но чем меньше блюпринтов «тикает» в течение каждого кадра, тем шустрее эта подмостки бегает.
Вот несколько ситуаций, когда можно использовать этот тип оптимизации:
- Предметы, которым необязательно работать, когда игрок на них не смотрит
- Процессы, какие выполняются в зависимости от игрового времени
- Неигровые персонажи (NPC), каким необязательно что-то делать, когда рядом нет игрока
В качестве самого несложного решения перед Event Tick можно поставить нод Was Recently Rendered. Таким манером, для того, чтобы наш Event Tick включался/выключался, нам не необходимо подключать к нему специальные события и детекторы. Кроме того, эта система по-прежнему может быть самостоятельна от других процессов, происходящих в сцене.
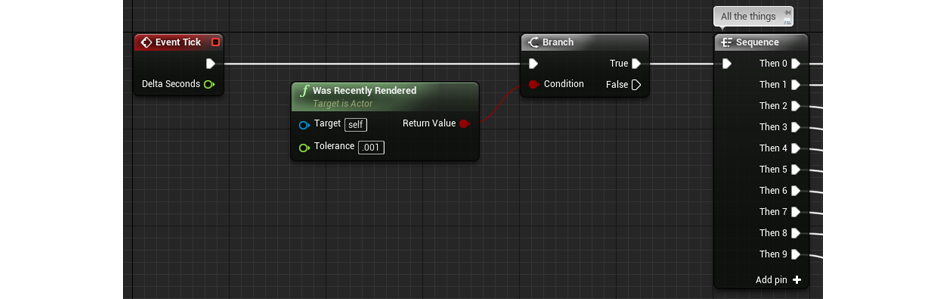
Управление нодом Event Tick с поддержкой проверки на рендер
Этот метод можно использовать и для немало сложных задач. К примеру, если у нас есть процесс, выполняющийся в подневольности от игрового времени (к примеру, какая-нибудь светящаяся кнопка, какая каждую секунду то загорается, то затухает), мы можем воспользоваться графом ниже:

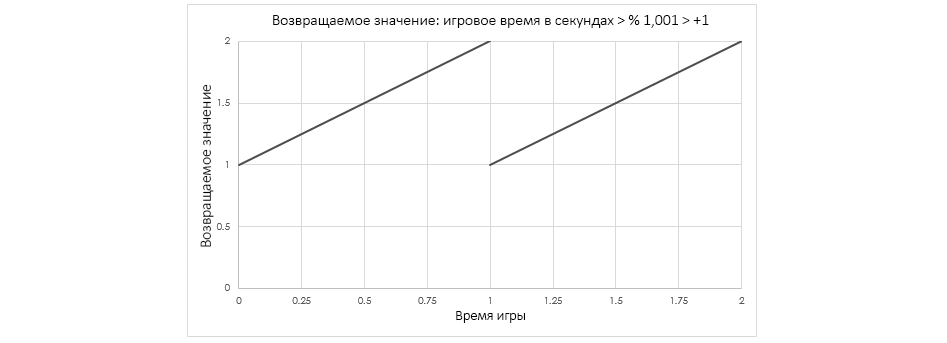
Смысл Emissive Value в Material Collection задано таким манером, что во время рендера оно будет работать как абсолютная синусоида игрового поре
Граф выше следит за тем, сколько прошло игрового поре, а затем пропускает это значение через абсолютный синус плюс кол, что в итоге дает синусную волну, варьирующуюся между смыслами «1» и «2».
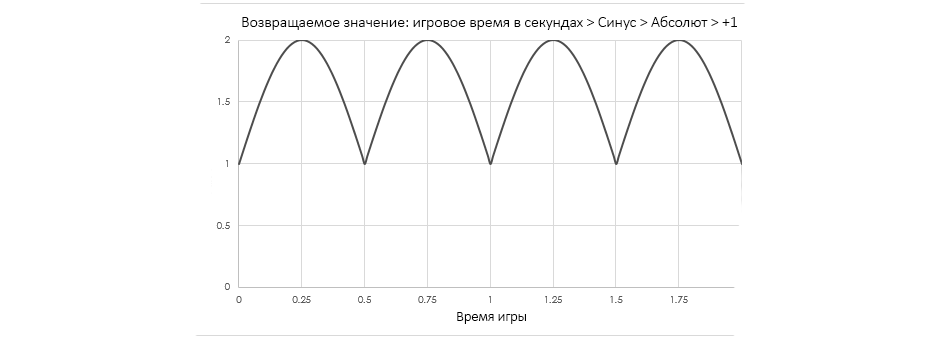
Преимущество этого метода в том, что мигание кнопки будет выходить в соответствии с линией на графике выше, причем независимо от того, глядит игрок на кнопку или нет (он может и вертеться кругами, и пристально на нее таращиться). И все благодаря смыслу, рассчитываемому на основе синуса игрового времени.
Это работает и с показателем степени, но в этом случае граф выглядит по-другому.
Проверку на рендер при поддержки нода Was Recently Rendered можно сделать и чуть запоздалее. То есть, если у объекта, которым управляет нод Event Tick, есть какие-то задачи, какие нужно выполнять каждый кадр, но можно сделать так, чтобы эти задачи выполнялись и до проверки на рендер (см. граф ниже). Чем меньше нодов будет вызываться с любым «тиком» нода Event Tick, тем лучше.

Использование проверки на рендер для управления визуальными фрагментами блюпринта
Еще одинешенек способ снизить «стоимость» блюпринта – это замедлить его и позволить ноду Event Tick «тикать» лишь один раз в течение определенного интервала. Этот интервал задается при поддержки нода Set Actor Tick Interval.
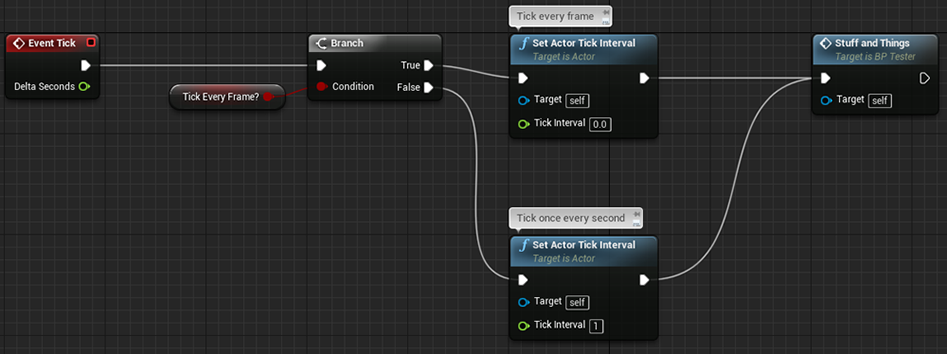
Переключение между интервалами
Кроме того, интервал, с каким «тикает» нод Event Tick, можно задать в пункте Tick Interval – он есть во вкладке Details у блюпринта, над которым вы работаете. Здесь интервал задается в секундах.
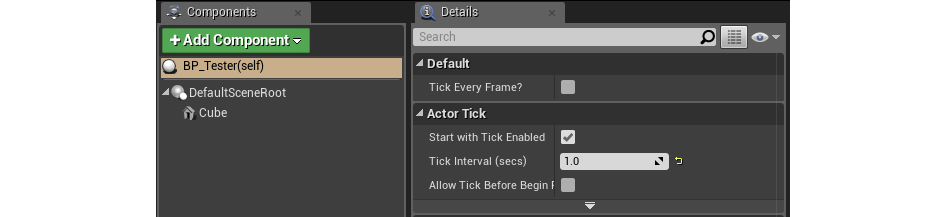
Пункт Tick Interval во вкладке Details
Это спокойно, к примеру, когда нужно сделать счетчик, срабатывающий любую секунду.

Создаем параллельный счетчик, срабатывающий каждую секунду
В качестве образца того, как этот тип оптимизации может снизить средний показатель мс, подавайте взглянем на граф ниже:

Невероятно полезный пример того, как мастерить не нужно
Здесь у нас нод ForLoop, который считает от «0» до «10000», и для него сквозь нод SET задано целое число Count. Этот граф весьма ресурсоемок и неэффективен – настолько, что показатель мс у нашей сцены составляет цельных 53,49 мс.

Просмотр в Stat Unit «стоимости» невероятно здорового примера
Перейдя в Profiler, мы понимаем почему. Этот несложный, но крайне неэффективный блюпринт за каждый тик «поедает» 43 мс.
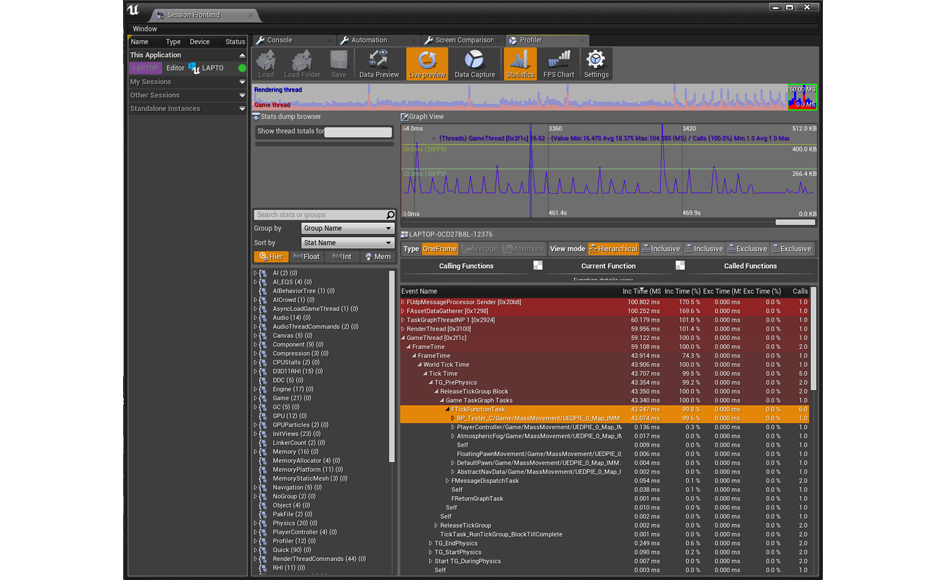
Просмотр в Profiler фрагмента, отвечающего за срабатывание Event Tick в любом кадре
Но если заставить этот блюпринт «тикать» любую секунду, то большую часть времени он будет «поедать» 0 мс. Если посмотреть на посредственнее время (выделите какой-нибудь фрагмент таймлайна в окне Graph View) за три «тика», мы увидим, что посредственный показатель составляет 0,716 мс.
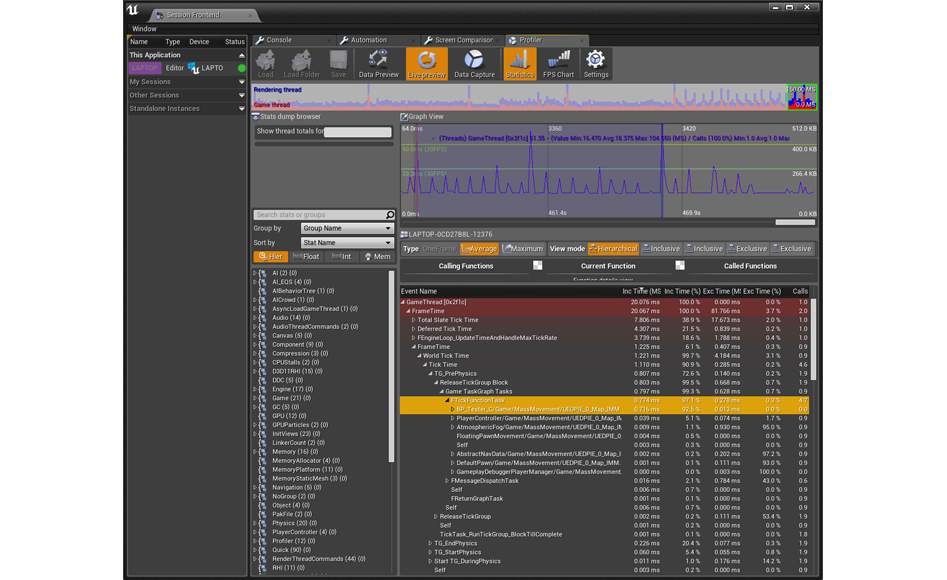
Просмотр в Profiler фрагмента, отвечающего за срабатывание Event Tick любую секунду
Или возьмем более распространенный случай: допустим, у нашего блюпринта 1,4 мс, и если подмостки будет работать на 60 фпс, то на обработку этого блюпринта будет уходить 84 мс. Но если убавить время, в течение которого у блюпринта «тикает» нод Event Tick, то это снизит и всеобщей время, затрачиваемое на обработку этого блюпринта.
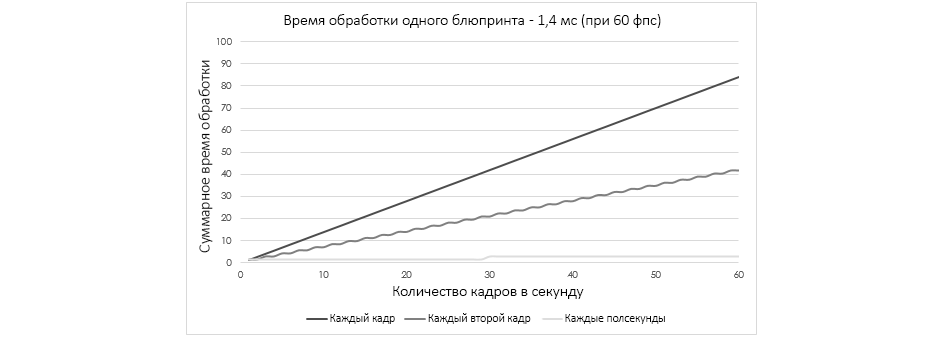
Массовое движение, нод ForLoop и многопоточность
Когда несколько моделей подвигаются одновременно, это выглядит очень здорово и может сделать визуальный манера очень привлекательным. Правда, в таком случае на CPU ложится вящая нагрузка, из-за чего в конечном счете страдает и фпс. Впрочем, это тоже можно оптимизировать, расшибив массовое движение на несколько блюпринтов – благодаря многопоточности и умению UE4 править рабочими потоками.
В этом разделе мы воспользуемся скриптом, какой будет динамически перемещать 1600 сфер-экземпляров вверх/книзу по модифицированной синусной кривой.
Ниже – простой скрипт, основывающий решетку. Просто добавляем компонент Instanced Static Mesh, во вкладке Details выбираем сетку, какую будем использовать, а затем добавляем следующие ноды:

Скрипт для создания несложный решетки
Создав решетку, добавляем этот скрипт во вкладку Event Graph.
Чету слов о ноде Update Instance Transform. Если какой-либо из экземпляров будет трансформирован, это изменение не будет показано, пока пункт Mark Render State Dirty не будет помечен как «true». Но это ресурсоемкая операция, т.к. проверка идет сквозь каждую сетку. Чтобы сэкономить вычислительные ресурсы, особенно если этот нод запускается по несколько раз за «тик», можно сделать так, чтобы сетки обновлялись в крышке блюпринта. В скрипте ниже пункт Mark Render State Dirty помечается как «true» лишь при соблюдении двух условий – если на ноде ForLoop стоит Last Index и если смысл в Index соответствует Grid Size минус 1.
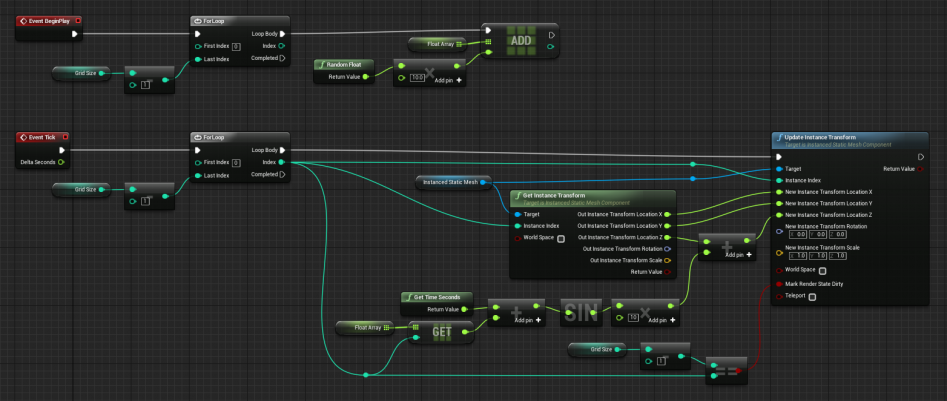
Блюпринт с динамическим движением для статических сеток-экземпляров
Кроме того, при поддержки блюпринта типа Actor, скрипта для создания решетки и события для динамического движения мы можем создать различные варианты решетки, где одновременно будет показываться 1600 сеток.

Несколько вариантов решетки с 1600 сетками
Запустив сцену, мы увидим элементы решетки, плавающие наверх и вниз.

Решетка из 1600 статических сеток-экземпляров, динамически подвигающихся вверх и вниз
Тем не менее, тип разбиения на фрагменты влияет на скорость, с какой работает сцена.
Во-первых, если решетка будет заключаться из 1600 отдельных фрагментов, то все 1600 блюпринтов будут обработаны за 16,86 мс (т.е. в посредственном 0,0105 мс на один блюпринт). То есть, хотя «цена» одного блюпринта невелика, их суммарное число замедляет систему. Единственная вещь, которую здесь можно сделать – это убавить количество блюпринтов, срабатывающих с каждым «тиком». Другая вина большой нагрузки заключается в большом количестве отдельных сеток, из-за чего увеличивается число и команд отрисовки, и команд для трансформации сетки.
Во-вторых, если решетка будет заключаться из одного фрагмента, в который входит 1600 сеток, то этот вариант будет весьма хорошо оптимизирован в плане команд отрисовки (потому что на всю решетку потребуется лишь одна команда отрисовки), но «стоимость» блюпринта, которому за одинешенек «тик» нужно будет обработать 1600 сеток, составит 19,63 мс.
Но если расшибить решетку по-другому (на 4 фрагмента на 400 сеток, на 64 по 25 или на 16 по 100), то итог получается более оптимизированным – благодаря уменьшенному времени обработки скрипта и умению UE4 трудиться с многопоточностью. Благодаря последней UE4 может распределять нагрузку по обработке блюпринтов по нескольким пролетариям потокам, тем самым эффективно используя все ядра CPU.
Если мы посмотрим на пора обработки блюпринтов и то, как они распределяются по рабочим потокам, то увидим вытекающее:
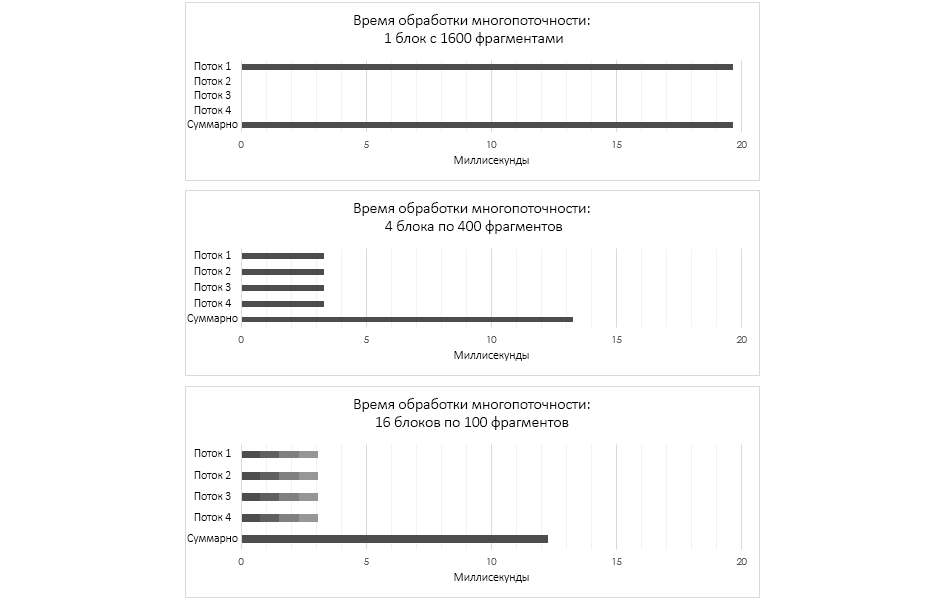
Структуры данных
Использование правильных структур данных – непременный элемент любой программы, и к разработке игр это относится в той же степени, как и к разработке прочего ПО. При программировании в UE4 используются блюпринты, и в массиве-шаблоне, который служит основным контейнером, никаких структур данных нет. Они создаются вручную на немало поздней стадии разработки – с добавлением функций и нодов, имеющихся в UE4.
Образец использования
В качестве примера того, почему и как структуру этих можно использовать в разработке игр, давайте представим игру в манере «шутемап». Одна из главных механик «шутемапов» – это пальба по врагам, которая генерирует тысячи пуль, носящихся по экрану. Поскольку пули в крышке концов достигают своих целей (или не достигают, врезаясь в какие-либо объекты) и разрушаются, игровой движок должен хорошенько прибираться за этим мусором, что может повлиять на производительность игры и даже повлечь снижение фреймрейта. Чтобы управиться с этой проблемой, разработчики должны предусмотреть в своем проекте так именуемый «объектный пул» – это набор объектов (в данном случае – пуль), помещенных в массив/список и возделываемых при запуске игры – благодаря которому разработчики могут вводить/выключать пули в любое время. В результате движку отводится лишь труд по созданию пуль.
Самый распространенный метод использования объектного пула – это взять первую, пока еще не включенную пулю в массиве/списке, переместить ее в стартовую позицию, включить ее, а затем выключить, когда она вылетит за экран или попадет во неприятеля. Проблема этого метода во времени, которое требуется на труд скрипта, т.е. в большом «О». Поскольку вы делаете много циклов, испытывая объекты и ища, какой из них нужно выключить, при использовании 5000 объектов на розыск одного объекта может уйти очень много циклов. У этого метода пора будет представлено в виде O(n), где «n» – это количество объектов в комплекте.
Хотя O(n) – это далеко не худший алгоритм. Чем ближе мы будем к O(1) – т.е. к фиксированной «стоимости», независящей от размера – тем немало эффективным будет скрипт и более шустрой будет игра. Чтобы провертеть этот прием вместе с объектным пулом, мы используем структуру этих, именуемую «очередью». Как и в настоящей очереди, эта структура данных берет первоначальный объект в наборе, использует его, а затем удаляет – и так до тех пор, пока не использует все объекты в очередности.
Используя эту «очередь» для нашего объектного пула, мы можем взять передний фрагмент комплекта, включить его, затем убрать и сразу же поместить его в заднюю доля набора. Это создаст в скрипте эффективный цикл и уменьшит пора работы скрипта до O(1). Мы также можем добавить к этому циклу проверку – если удаленный объект был включен, то скрипт берет его и, не основывая новый объект, помещает в конец очереди, увеличивая размер комплекта, но не увеличивая времени обработки скрипта.
Очереди
Ниже – несколько картинок, какие демонстрируют, как использовать очереди. В них к блюпринтам добавляются различные функции, какие делают код более «чистым» и придают ему возможность повторного использования.
- Удаление

Реализация конструкции queue::pop в блюпринте UE4; удаляет элемент с переднего крышки очереди
- Добавление

Реализация конструкции queue::push в блюпринте UE4; вставляет новоиспеченный элемент в конец очереди
- Определение того, пуста ли очередность

- Определение размера очереди

Реализация конструкции queue::size в блюпринте UE4; сообщает размер очередности
- Возвращение указателя на первый элемент в очереди

Реализация конструкции queue::front в блюпринте UE4; возвращает указатель на первоначальный элемент в очереди
- Возвращение указателя на последний элемент в очередности

Реализация конструкции queue::back в блюпринте UE4; возвращает указатель на заключительный элемент в очереди
- Вставка элемента в определенное место очередности
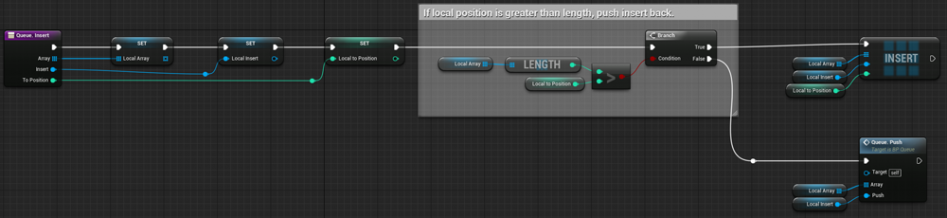
Вставляет указанный элемент в указанное место очереди (с проверкой позиции)
- Мена данными
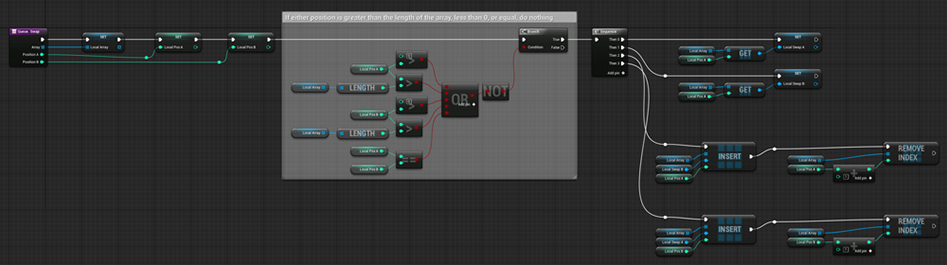
Реализация конструкции queue::swap в блюпринте UE4; заставляет два контейнера поменяться данными (с проверкой позиции)
Стеки
Ниже – несколько картинок, какие демонстрируют, как использовать стеки. В них к блюпринтам добавляются различные функции, какие делают код более «чистым» и придают ему возможность повторного использования.
- Удаление

Реализация конструкции stack::pop в блюпринте UE4; удаляет элемент с переднего крышки стека
- Добавление

Реализация конструкции stack::push в блюпринте UE4; вставляет новоиспеченный элемент в конец стека
- Определение того, пуст ли стек

Реализация конструкции stack::empty в блюпринте UE4; сообщает, пуст ли стек
- Дефиниция размера стека

Реализация конструкции stack::size в блюпринте UE4; сообщает размер стека
- Возвращение указателя на заключительный элемент в стеке

Возвращает указатель на последний элемент в стеке
- Вставка элемента в определенное пункт стека
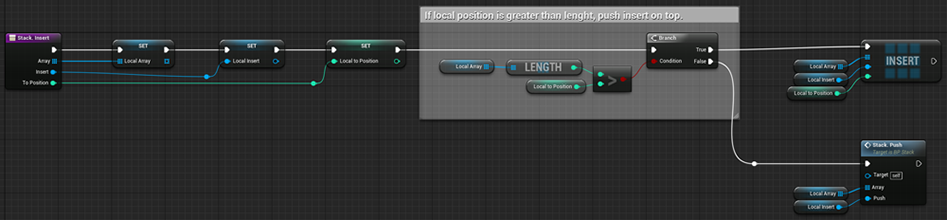
Вставляет указанный элемент в указанное место стека (с проверкой позиции)
Авторы статьи — сотрудники Intel Эррин М. (Errin M) и Джефф Роус (Jeff Rous).
Оригинал можно прочесть тут.
Прочитайте по теме ещё:
 Inner Chains – мистический хоррор на Unreal Engine 4 обзавелся датой релиза и новым кинематографическим трейлером
Inner Chains – мистический хоррор на Unreal Engine 4 обзавелся датой релиза и новым кинематографическим трейлером
 Final Fantasy XV – оптимизация была улучшена
Final Fantasy XV – оптимизация была улучшена
 Shin Megami Tensei – Atlus создает юбилейную RPG для Nintendo Switch на движке Unreal Engine 4, еще одна новая часть готовится для 3DS
Shin Megami Tensei – Atlus создает юбилейную RPG для Nintendo Switch на движке Unreal Engine 4, еще одна новая часть готовится для 3DS
 Redeemer – зрелищный и кровавый экшен на Unreal Engine 4 готовится выйти на PC
Redeemer – зрелищный и кровавый экшен на Unreal Engine 4 готовится выйти на PC